1.3. spaCy’s Pipelines#
Now that we understand the basics of spaCy’s linguistic features, let’s explore pipelines in spaCy. As we have seen, spaCy offers both heuristic (rules-based) and machine learning natural language processing solutions. These solutions are activated by pipes. Here, we will explore pipes and pipelines generally and the ones offered by spaCy specifically. In the next chapter, we will explore how you can create custom pipes and add them to a spaCy pipeline. Before we jump in, let’s import spaCy.
import spacy
1.3.1. Standard Pipes (Components and Factories) Available from spaCy#
SpaCy is much more than an NLP framework. It is also a way of designing and implementing complex pipelines.
A pipe is a component of a pipeline. A pipeline’s purpose is to take input data, perform some sort of operations on that input data, and then output those operations either as a new data or extracted metadata. A pipe is an individual component of a pipeline. In the case of spaCy, there are a few different pipes that perform different tasks. The tokenizer, tokenizes the text into individual tokens; the parser, parses the text, and the NER identifies entities and labels them accordingly. All of this data is stored in the Doc object as we saw in Notebook 01_01 of this series.
It is important to remember that pipelines are sequential. This means that components earlier in a pipeline affect what later components receive. Sometimes this sequence is essential, meaning later pipes depend on earlier pipes. At other times, this sequence is not essential, meaning later pipes can function without earlier pipes. It is important to keep this in mind as you create custom spaCy models (or any pipeline for that matter).
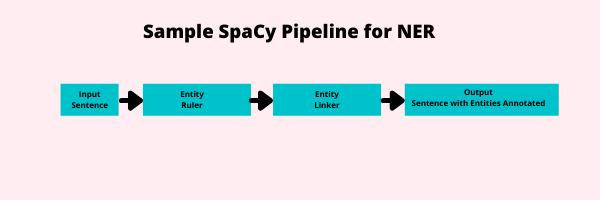
Fig. 1.18 Example of an NER Pipeline#
Here, we see an input, in this case a sentence, enter the pipeline from the left. Two pipes are activated on this, a rules-based named entity recognizer known as an EntityRuler which finds entities and an EntityLinker pipe that identifies what entity that is to perform toponym resolution. The sentence is then outputted with the sentence and the entities annotated. At this point, we could use the doc.ents feature to find the entities in our sentence. In spaCy, you will often use pipelines that are more sophisticated than this. You will specifically use a Tok2Vec input layer to vectorize your input sentence. This will allow machine learning pipes to make predictions.
Below is a complete list of the AttributeRuler pipes available to you from spaCy and the Matchers.
1.3.1.1. Attribute Rulers#
Dependency Parser
EntityLinker
EntityRecognizer
EntityRuler
Lemmatizer
Morpholog
SentenceRecognizer
Sentencizer
SpanCategorizer
Tagger
TextCategorizer
Tok2Vec
Tokenizer
TrainablePipe
Transformer
1.3.1.2. Matchers#
DependencyMatcher
Matcher
PhraseMatcher
1.3.2. How to Add Pipes#
In most cases, you will use an off-the-shelf spaCy model. In some cases, however, an off-the-shelf model will not fill your needs or will perform a specific task very slowly. A good example of this is sentence tokenization. Imagine if you had a document that was around 1 million sentences long. Even if you used the small English model, your model would take a long time to process those 1 million sentences and separate them. In this instance, you would want to make a blank English model and simply add the Sentencizer to it. The reason is because each pipe in a pipeline will be activated (unless specified) and that means that each pipe from Dependency Parser to named entity recognition will be performed on your data. This is a serious waste of computational resources and time. The small model may take hours to achieve this task. By creating a blank model and simply adding a Sentencizer to it, you can reduce this time to merely minutes.
To demonstrate this process, let’s first create a blank model.
nlp = spacy.blank("en")
Here, notice that we have used spacy.blank, rather than spacy.load. When we create a blank model, we simply pass the two letter combination for a language, in this case, en for English. Now, let’s use the add_pipe() command to add a new pipe to it. We will simply add a sentencizer.
nlp.add_pipe("sentencizer")
<spacy.pipeline.sentencizer.Sentencizer at 0x7fd926ca9840>
import requests
from bs4 import BeautifulSoup
s = requests.get("https://ocw.mit.edu/ans7870/6/6.006/s08/lecturenotes/files/t8.shakespeare.txt")
soup = BeautifulSoup(s.content).text.replace("-\n", "").replace("\n", " ")[:100000]
%%time
doc = nlp(soup)
print(len(list(doc.sents)))
500
CPU times: user 155 ms, sys: 3.84 ms, total: 159 ms
Wall time: 157 ms
nlp2 = spacy.load("en_core_web_sm")
%%time
doc = nlp2(soup)
print (len(list(doc.sents)))
781
CPU times: user 2.99 s, sys: 79.5 ms, total: 3.07 s
Wall time: 3.07 s
The difference in time here is remarkable. Our text string was 100,000 characters. The blank model with just the Sentencizer completed its task in 159 milliseconds and found 781 sentences. The small English model, the most efficient one offered by spaCy, did the same task in 3.07 seconds and found 781 sentences. The small English model, in other words, took much longer. This time increases significantly as your texts get larger. The reason for this large difference in time is the other components active in the spaCy pipeline, such as the POS Tagger and NER pipes.
Often times you need to find sentences quickly, not necessarily accurately. In these instances, it makes sense to know tricks like the one above.
1.3.3. Examining a Pipeline#
In spaCy, we have a few different ways to study a pipeline. If we want to do this in a script, we can do the following command:
nlp2.analyze_pipes()
{'summary': {'tok2vec': {'assigns': ['doc.tensor'],
'requires': [],
'scores': [],
'retokenizes': False},
'tagger': {'assigns': ['token.tag'],
'requires': [],
'scores': ['tag_acc'],
'retokenizes': False},
'parser': {'assigns': ['token.dep',
'token.head',
'token.is_sent_start',
'doc.sents'],
'requires': [],
'scores': ['dep_uas',
'dep_las',
'dep_las_per_type',
'sents_p',
'sents_r',
'sents_f'],
'retokenizes': False},
'attribute_ruler': {'assigns': [],
'requires': [],
'scores': [],
'retokenizes': False},
'lemmatizer': {'assigns': ['token.lemma'],
'requires': [],
'scores': ['lemma_acc'],
'retokenizes': False},
'ner': {'assigns': ['doc.ents', 'token.ent_iob', 'token.ent_type'],
'requires': [],
'scores': ['ents_f', 'ents_p', 'ents_r', 'ents_per_type'],
'retokenizes': False}},
'problems': {'tok2vec': [],
'tagger': [],
'parser': [],
'attribute_ruler': [],
'lemmatizer': [],
'ner': []},
'attrs': {'token.lemma': {'assigns': ['lemmatizer'], 'requires': []},
'doc.sents': {'assigns': ['parser'], 'requires': []},
'token.is_sent_start': {'assigns': ['parser'], 'requires': []},
'token.dep': {'assigns': ['parser'], 'requires': []},
'token.tag': {'assigns': ['tagger'], 'requires': []},
'doc.ents': {'assigns': ['ner'], 'requires': []},
'token.ent_iob': {'assigns': ['ner'], 'requires': []},
'token.head': {'assigns': ['parser'], 'requires': []},
'doc.tensor': {'assigns': ['tok2vec'], 'requires': []},
'token.ent_type': {'assigns': ['ner'], 'requires': []}}}
Note the dictionary structure. This tells us not only what is inside the pipeline, but its order. Each key after “summary” is a pipe. The value is a dictionary. This dictionary tells us a few different things. All of these value dictionaries state: “assigns” which corresponds to a value of what that particular pipe assigns to the token and doc as it passes through the pipeline. In some cases, there will be a key of “scores” in the dictionary. This indicates how the machine learning model was evaluated.
1.3.4. Conclusion#
This chapter has given you an umbrella overview of spaCy. Over the next two chapters, we will deep dive into specific areas and use spaCy to solve general and domain-specific problems in the digital humanities.