4.3. Time Series Data#
4.3.1. What is Time Series Data#
Time series data is data that reflects either time or dates. In Pandas this type of data is known as datetime. If you are working with time series data, as we shall see, there are significant reasons to ensure that Pandas understands that the data at hand is a date or a time. It allows for easily manipulation and cleaning of inconsistent data formatting. Let us consider a simple example. Imagine we were given dates from one source as 01/02/2002 and another as 01.02.2002. Both are valid date formats, but they are structured entirely differently. Imagine now you had a third dataset that organized the data as 2 January 2002. Your task is to merge all these datasets together.
If you wanted to do that, you could write out some Python and script them into alignment, but Pandas offers the ability to do that automatically. In order to leverage that ability, however, you must tell Pandas that the data at hand is datetime data. Exactly how you do that, we will learn in this chapter.
Time series data is important for many different aspects of industry and academia. In the financial sector, time series data allows for one to understand the past performance of a stock. This is particularly useful in machine learning predictions which need to understand the past to predict accurately the future. More importantly, they need to understand the past a sequence of data. In the humanities, time series data is important for understand historical context and, as we shall see, plotting data temporally. Understanding how to work with time series data, therefore, in Pandas is absolutely essential.
4.3.2. About the Dataset#
In this chapter, we will be working with an early version of a dataset I helped cultivate at the Bitter Aloe Project, a digital humanities project that explores apartheid violence in South Africa during the 20th century. This dataset comes from Vol. 7 of the Truth and Reconciliation Commission’s Final Report. I am using not our final, well-cleaned version of this dataset, rather an earlier version for one key reason. It contains problematic cells and structure. This is more reflective of real-world data, which will often times come from multiple sources and need to be cleaned and structured. As such, it is good practice in this chapter to try and address some of the common problems that you will encounter with time series data.
import pandas as pd
df = pd.read_csv("../data/trc.csv")
df
| ObjectId | Last | First | Description | Place | Yr | Homeland | Province | Long | Lat | HRV | ORG | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | AARON | Thabo Simon | An ANCYL member who was shot and severely inju... | Bethulie | 1991.0 | NaN | Orange Free State | 25.97552 | -30.503290 | shoot|injure | ANC|ANCYL|Police|SAP |
| 1 | 2 | ABBOTT | Montaigne | A member of the SADF who was severely injured ... | Messina | 1987.0 | NaN | Transvaal | 30.039597 | -22.351308 | injure | SADF |
| 2 | 3 | ABRAHAM | Nzaliseko Christopher | A COSAS supporter who was kicked and beaten wi... | Mdantsane | 1985.0 | Ciskei | Cape of Good Hope | 27.6708791 | -32.958623 | beat | COSAS|Police |
| 3 | 4 | ABRAHAMS | Achmat Fardiel | Was shot and blinded in one eye by members of ... | Athlone | 1985.0 | NaN | Cape of Good Hope | 18.50214 | -33.967220 | shoot|blind | SAP |
| 4 | 5 | ABRAHAMS | Annalene Mildred | Was shot and injured by members of the SAP in ... | Robertson | 1990.0 | NaN | Cape of Good Hope | 19.883611 | -33.802220 | shoot|injure | Police|SAP |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 20829 | 20888 | XUZA | Mandla | Was severely injured when he was stoned by a f... | Carletonville | 1991.0 | NaN | Transvaal | 27.397673 | -26.360943 | injure|stone | ANC |
| 20830 | 20889 | YAKA | Mbangomuni | An IFP supporter and acting induna who was sho... | Mvutshini | 1993.0 | KwaZulu | Natal | 30.28172 | -30.868900 | shoot | NaN |
| 20831 | 20890 | YALI | Khayalethu | Was shot by members of the SAP in Lingelihle, ... | Cradock | 1986.0 | NaN | Cape of Good Hope | 25.619176 | -32.164221 | shoot | SAP |
| 20832 | 20891 | YALO | Bikiwe | An IFP supporter whose house and possessions w... | Port Shepstone | 1994.0 | NaN | Natal | 30.4297304 | -30.752126 | destroy | ANC |
| 20833 | 20892 | YALOLO-BOOYSEN | Geoffrey Yali | An ANC supporter and youth activist who was to... | George | 1986.0 | NaN | Cape of Good Hope | 22.459722 | -33.964440 | torture|detain|torture | ANC|SAP |
20834 rows × 12 columns
As we can see, we have a few different columns which are relatively straight forward. In this notebook, however, I want to focus on Yr, which is a column that contains a single year referenced within the description. This corresponds to the year in which the violence described occurred. Notice, however, that we have a problem. Year is being recognized as a float (a number with a decimal place), or floating number. To confirm our suspicion, let’s take a look at the data types by using the following command.
display(df.dtypes)
ObjectId int64
Last object
First object
Description object
Place object
Yr float64
Homeland object
Province object
Long object
Lat float64
HRV object
ORG object
dtype: object
Here, we can see all the different columns and their corresponding data types. Notice that Yr has float64. This confirms our suspicion. Why is this a problem? Well, if we were to try and plot the data by year (see the bar graph below), we would have floating numbers in that graph. This does not look clean. We could manually adjust these years to have no decimal place, but that requires effort on a case-by-case basis. Instead, it is best practice to convert these floats either to integers or to datetime data. Both have their advantages, but if your end goal is larger data analysis on time series data (not just plotting the years), I would opt for the latter. In order to do either, however, we must clean the data to get it into the correct format.
df['Yr'].value_counts().sort_index().plot.bar(figsize=(20,5))
<AxesSubplot:>
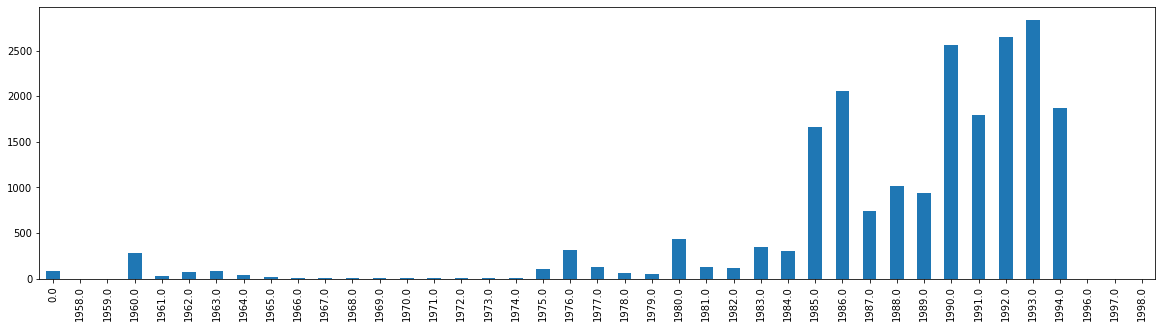
4.3.3. Cleaning the Data from Float to Int#
Let’s first try and convert our float column into an integer column. If we execute the command below which would normally achieve this task, we get the following error.
df['Yr'] = df['Yr'].astype(int)
---------------------------------------------------------------------------
IntCastingNaNError Traceback (most recent call last)
<ipython-input-4-dc1db5c67903> in <module>
----> 1 df['Yr'] = df['Yr'].astype(int)
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\generic.py in astype(self, dtype, copy, errors)
5804 else:
5805 # else, only a single dtype is given
-> 5806 new_data = self._mgr.astype(dtype=dtype, copy=copy, errors=errors)
5807 return self._constructor(new_data).__finalize__(self, method="astype")
5808
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\internals\managers.py in astype(self, dtype, copy, errors)
412
413 def astype(self: T, dtype, copy: bool = False, errors: str = "raise") -> T:
--> 414 return self.apply("astype", dtype=dtype, copy=copy, errors=errors)
415
416 def convert(
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\internals\managers.py in apply(self, f, align_keys, ignore_failures, **kwargs)
325 applied = b.apply(f, **kwargs)
326 else:
--> 327 applied = getattr(b, f)(**kwargs)
328 except (TypeError, NotImplementedError):
329 if not ignore_failures:
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\internals\blocks.py in astype(self, dtype, copy, errors)
590 values = self.values
591
--> 592 new_values = astype_array_safe(values, dtype, copy=copy, errors=errors)
593
594 new_values = maybe_coerce_values(new_values)
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\dtypes\cast.py in astype_array_safe(values, dtype, copy, errors)
1307
1308 try:
-> 1309 new_values = astype_array(values, dtype, copy=copy)
1310 except (ValueError, TypeError):
1311 # e.g. astype_nansafe can fail on object-dtype of strings
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\dtypes\cast.py in astype_array(values, dtype, copy)
1255
1256 else:
-> 1257 values = astype_nansafe(values, dtype, copy=copy)
1258
1259 # in pandas we don't store numpy str dtypes, so convert to object
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\dtypes\cast.py in astype_nansafe(arr, dtype, copy, skipna)
1166
1167 elif np.issubdtype(arr.dtype, np.floating) and np.issubdtype(dtype, np.integer):
-> 1168 return astype_float_to_int_nansafe(arr, dtype, copy)
1169
1170 elif is_object_dtype(arr):
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\dtypes\cast.py in astype_float_to_int_nansafe(values, dtype, copy)
1211 """
1212 if not np.isfinite(values).all():
-> 1213 raise IntCastingNaNError(
1214 "Cannot convert non-finite values (NA or inf) to integer"
1215 )
IntCastingNaNError: Cannot convert non-finite values (NA or inf) to integer
At the very bottom, we see why the error was returned. “IntCastingNaNError: Cannot convert non-finite values (NA or inf) to integer”. This means that somewhere in our data, there are a few blank cells in the Year column. We need to fill in these blank cells. To do that, we can use the fillna function that we met earlier in this textbook.
df = df.fillna(0)
If we try and rerun our same command as above, you will notice we have no errors.
df['Yr'] = df['Yr'].astype(int)
Now, let’s see if it worked by displaying the data types again.
display(df.dtypes)
ObjectId int64
Last object
First object
Description object
Place object
Yr int32
Homeland object
Province object
Long object
Lat float64
HRV object
ORG object
dtype: object
Notice that Yr is now int32. Success! Now that we have the data in the correct format, let’s plot it out. We can plot out the frequency of violence based on year by using value counts. This will go through the entire Yr column and count all the values identified and store them as a dictionary of frequencies.
df['Yr'].value_counts()
1993 2835
1992 2648
1990 2556
1986 2056
1994 1867
1991 1793
1985 1665
1988 1015
1989 935
1987 744
1980 438
1983 352
1976 319
1984 301
1960 280
1977 128
1981 124
1982 123
1975 111
1963 88
0 84
1962 69
1978 60
1979 53
1964 37
1961 32
1965 19
1969 14
1968 14
1974 12
1966 11
1970 10
1971 10
1967 8
1972 6
1973 5
1959 3
1998 3
1996 3
1997 2
1958 1
Name: Yr, dtype: int64
This looks great, but let’s try and plot it.
df['Yr'].value_counts().plot.bar(figsize=(20,5))
<AxesSubplot:>
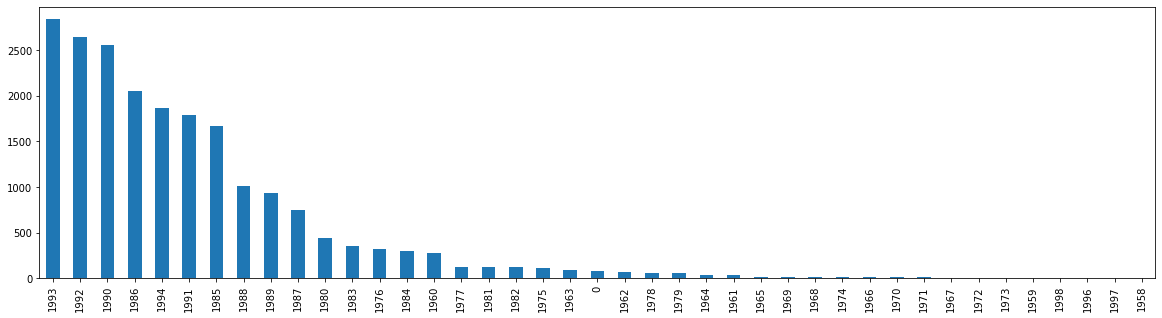
What do you notice that is horribly wrong about our bar graph? If you noticed that it is not chronological, you’d be right. It would be quite odd to present our data in this format. When we are examining time series data, we need to visualize that data chronologically (usually). We can fix this, by adding sort_index().
df['Yr'].value_counts().sort_index()
0 84
1958 1
1959 3
1960 280
1961 32
1962 69
1963 88
1964 37
1965 19
1966 11
1967 8
1968 14
1969 14
1970 10
1971 10
1972 6
1973 5
1974 12
1975 111
1976 319
1977 128
1978 60
1979 53
1980 438
1981 124
1982 123
1983 352
1984 301
1985 1665
1986 2056
1987 744
1988 1015
1989 935
1990 2556
1991 1793
1992 2648
1993 2835
1994 1867
1996 3
1997 2
1998 3
Name: Yr, dtype: int64
Notice that we have now preserved the value counts, but organized them in their correct order. We can now try plotting that data.
df['Yr'].value_counts().sort_index().plot.bar(figsize=(20,5))
<AxesSubplot:>
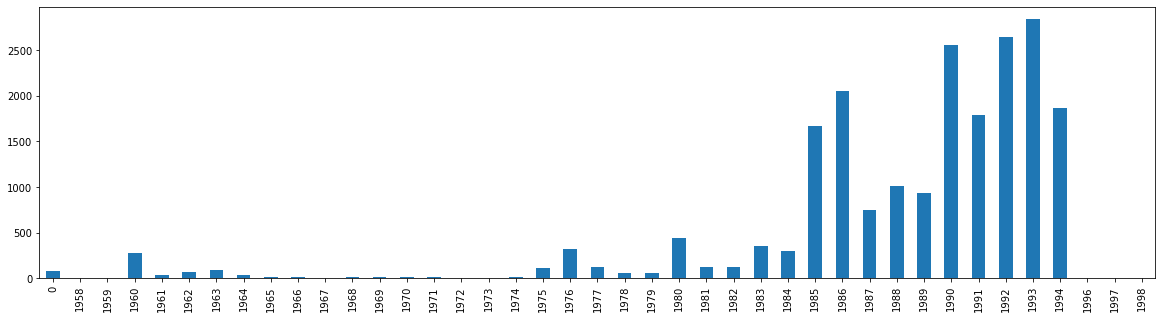
We have a potential issue, however. That first row, 0, is throwing off our bar graph. What if I didn’t want to represent 0, or no date, in the graph. I can solve this problem a few different ways. Let’s first create a new dataframe called val_year.
val_year = df["Yr"].value_counts().sort_index()
val_year
0 84
1958 1
1959 3
1960 280
1961 32
1962 69
1963 88
1964 37
1965 19
1966 11
1967 8
1968 14
1969 14
1970 10
1971 10
1972 6
1973 5
1974 12
1975 111
1976 319
1977 128
1978 60
1979 53
1980 438
1981 124
1982 123
1983 352
1984 301
1985 1665
1986 2056
1987 744
1988 1015
1989 935
1990 2556
1991 1793
1992 2648
1993 2835
1994 1867
1996 3
1997 2
1998 3
Name: Yr, dtype: int64
With this new dataframe, I can simply start at index 1 and then graph the data. Notice that the 0 value is now gone.
val_year.iloc[1:].plot.bar(figsize=(20,5))
<AxesSubplot:>
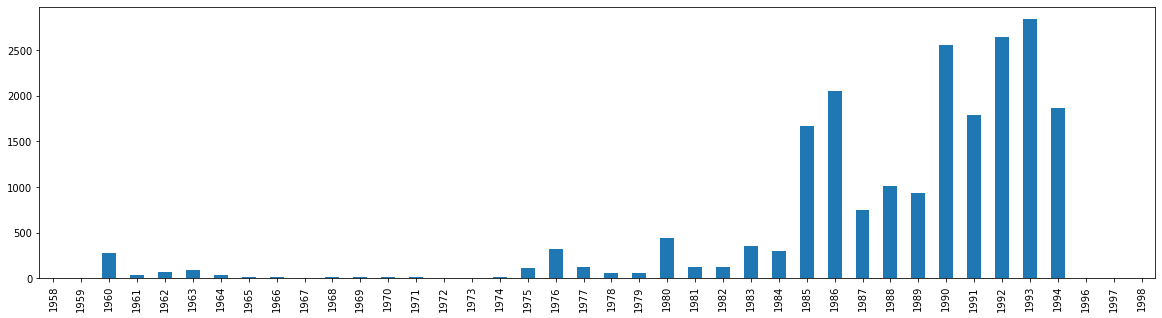
Although we have been able to now plot our time series data chronologically, Pandas has not seen this as a datetime type. Instead, it has viewed these years solely as integers. In order to work with the years as time series data formally, we need to convert the integers into datetime format.
4.3.4. Convert to Time Series DateTime in Pandas#
Our goal here will be to create a new column that will store Yr as a datetime type. One might think that we could easily just convert everything to datetime. Normally the following command would work, but instead we get this error.
df['Dates'] = pd.to_datetime(df['Yr'], format='%Y')
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\tools\datetimes.py in _to_datetime_with_format(arg, orig_arg, name, tz, fmt, exact, errors, infer_datetime_format)
508 try:
--> 509 values, tz = conversion.datetime_to_datetime64(arg)
510 dta = DatetimeArray(values, dtype=tz_to_dtype(tz))
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\_libs\tslibs\conversion.pyx in pandas._libs.tslibs.conversion.datetime_to_datetime64()
TypeError: Unrecognized value type: <class 'int'>
During handling of the above exception, another exception occurred:
ValueError Traceback (most recent call last)
<ipython-input-14-cc2c68a810bf> in <module>
----> 1 df['Dates'] = pd.to_datetime(df['Yr'], format='%Y')
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\tools\datetimes.py in to_datetime(arg, errors, dayfirst, yearfirst, utc, format, exact, unit, infer_datetime_format, origin, cache)
881 result = result.tz_localize(tz) # type: ignore[call-arg]
882 elif isinstance(arg, ABCSeries):
--> 883 cache_array = _maybe_cache(arg, format, cache, convert_listlike)
884 if not cache_array.empty:
885 result = arg.map(cache_array)
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\tools\datetimes.py in _maybe_cache(arg, format, cache, convert_listlike)
193 unique_dates = unique(arg)
194 if len(unique_dates) < len(arg):
--> 195 cache_dates = convert_listlike(unique_dates, format)
196 cache_array = Series(cache_dates, index=unique_dates)
197 # GH#39882 and GH#35888 in case of None and NaT we get duplicates
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\tools\datetimes.py in _convert_listlike_datetimes(arg, format, name, tz, unit, errors, infer_datetime_format, dayfirst, yearfirst, exact)
391
392 if format is not None:
--> 393 res = _to_datetime_with_format(
394 arg, orig_arg, name, tz, format, exact, errors, infer_datetime_format
395 )
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\tools\datetimes.py in _to_datetime_with_format(arg, orig_arg, name, tz, fmt, exact, errors, infer_datetime_format)
511 return DatetimeIndex._simple_new(dta, name=name)
512 except (ValueError, TypeError):
--> 513 raise err
514
515
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\tools\datetimes.py in _to_datetime_with_format(arg, orig_arg, name, tz, fmt, exact, errors, infer_datetime_format)
498
499 # fallback
--> 500 res = _array_strptime_with_fallback(
501 arg, name, tz, fmt, exact, errors, infer_datetime_format
502 )
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\core\tools\datetimes.py in _array_strptime_with_fallback(arg, name, tz, fmt, exact, errors, infer_datetime_format)
434
435 try:
--> 436 result, timezones = array_strptime(arg, fmt, exact=exact, errors=errors)
437 if "%Z" in fmt or "%z" in fmt:
438 return _return_parsed_timezone_results(result, timezones, tz, name)
c:\users\wma22\appdata\local\programs\python\python39\lib\site-packages\pandas\_libs\tslibs\strptime.pyx in pandas._libs.tslibs.strptime.array_strptime()
ValueError: time data '0' does not match format '%Y' (match)
Just as the NaN cells plagued us above, so too has the 0s that we filled them with. Fortunately, we can fix this issue by passing the keyword argument errors=”coerce”.
df['Dates'] = pd.to_datetime(df['Yr'], format='%Y', errors="coerce")
display(df.dtypes)
ObjectId int64
Last object
First object
Description object
Place object
Yr int32
Homeland object
Province object
Long object
Lat float64
HRV object
ORG object
Dates datetime64[ns]
dtype: object
And like magic, we have not only created a new column, but notice that it is in datetime64[ns] format. We should also understand the keyword argument passed here, format. Format takes a formatted string that will tell Pandas how to interpret the data being passed to it. Because our integer referred to a single year, we use %Y. Let’s try and plot this data now to see how it looks.
df['Dates'].value_counts().sort_index().plot.bar(figsize=(20,5))
<AxesSubplot:>
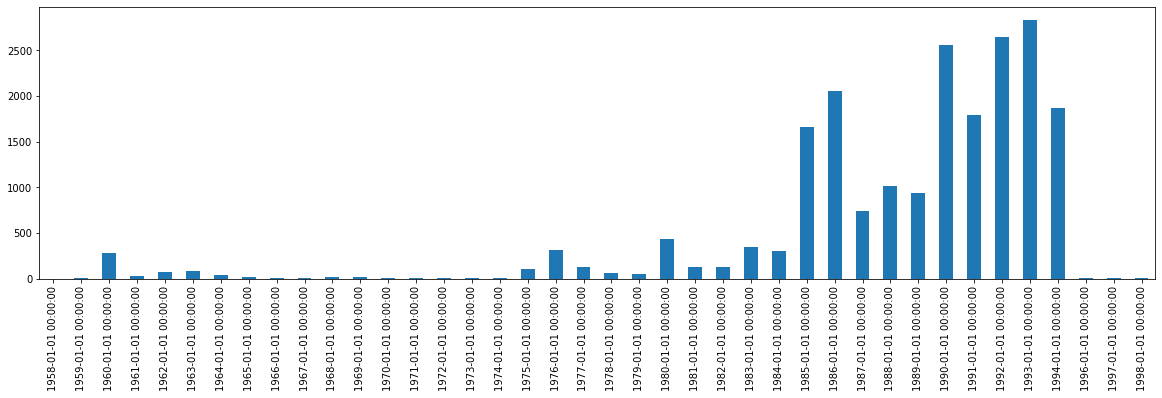
While this data is now plotted as Pandas-structured time series data, it does not look good. Our dates are rendered in the long, full format that has both the date (in its entirety) and the time. Let’s fix this by first, extracting the relevant data. In this case, the year and the counts.
new_df = df['Dates'].value_counts().sort_index()
new_df
1958-01-01 1
1959-01-01 3
1960-01-01 280
1961-01-01 32
1962-01-01 69
1963-01-01 88
1964-01-01 37
1965-01-01 19
1966-01-01 11
1967-01-01 8
1968-01-01 14
1969-01-01 14
1970-01-01 10
1971-01-01 10
1972-01-01 6
1973-01-01 5
1974-01-01 12
1975-01-01 111
1976-01-01 319
1977-01-01 128
1978-01-01 60
1979-01-01 53
1980-01-01 438
1981-01-01 124
1982-01-01 123
1983-01-01 352
1984-01-01 301
1985-01-01 1665
1986-01-01 2056
1987-01-01 744
1988-01-01 1015
1989-01-01 935
1990-01-01 2556
1991-01-01 1793
1992-01-01 2648
1993-01-01 2835
1994-01-01 1867
1996-01-01 3
1997-01-01 2
1998-01-01 3
Name: Dates, dtype: int64
Next, we need to convert that data into a new DataFrame.
new_df = pd.DataFrame(new_df)
new_df.head()
| Dates | |
|---|---|
| 1958-01-01 | 1 |
| 1959-01-01 | 3 |
| 1960-01-01 | 280 |
| 1961-01-01 | 32 |
| 1962-01-01 | 69 |
Now that we have that new DataFrame created, let’s fix our column name and change Dates to ViolentActs.
new_df = new_df.rename(columns={"Dates": "ViolentActs"})
new_df.head()
| ViolentActs | |
|---|---|
| 1958-01-01 | 1 |
| 1959-01-01 | 3 |
| 1960-01-01 | 280 |
| 1961-01-01 | 32 |
| 1962-01-01 | 69 |
With the new DataFrame, we can also fix the index so that it is strictly the year. Because Pandas knows that the index is a datetime type, then we can use the extra method, year, to grab just the year.
new_df.index = new_df.index.year
new_df.head()
| ViolentActs | |
|---|---|
| 1958 | 1 |
| 1959 | 3 |
| 1960 | 280 |
| 1961 | 32 |
| 1962 | 69 |
Notice that our data is now just the year, the only piece of data in the time series data that matters to us. With that new DataFrame in the correct format, we can now plot it.
new_df.plot.bar(figsize=(20,5))
<AxesSubplot:>
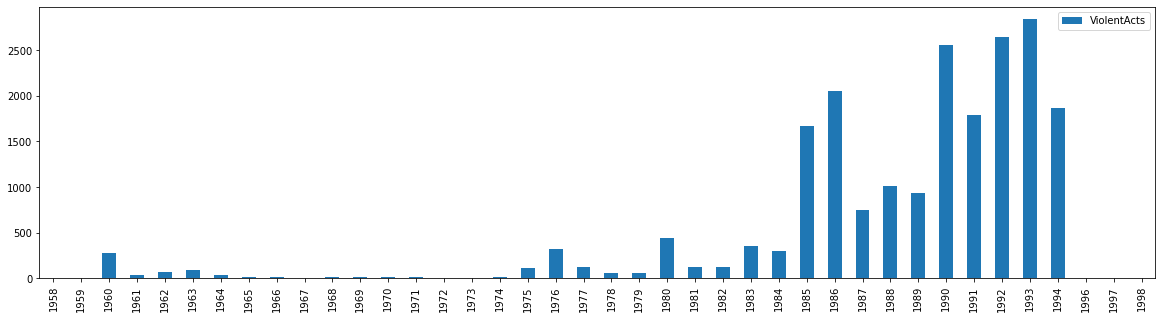
And thus we have successfully plotted our datetime data after properly formatting it in Pandas. While working with time series data in Pandas as a datetime can be a bit more complex in the beginning, it allows for you to more advanced things, such as we saw above by calling the year with .year. As we will see in the next few chapters, there are other advantages as well.